Как собрать качественную семантику для информационного портала

Здравствуйте, уважаемые читатели блога!
В этой статье мы поговорим о сборе качественного и релевантного семантического ядра для информационного портала.
Проработанная семантика помогает поисковым роботам индексировать сайт, и ранжировать его по топовым позициям в поисковой выдаче.
Однако, сбор качественных ключевых слов для семантического ядра (СЯ) информационного портала — проблема веб-мастеров и SEO-специалистов. Это связано со спецификой таких ресурсов, существенными затратами времени и сил на составление и обработку семантики. Важная проблема состоит также в определении средств для очистки СЯ от “мусорных” фраз.
Дальше по тексту мы разработаем стратегии оперативного сбора СЯ, и эффективные методы отсеивания нерелевантных или некачественных ключевиков.

Проблематика информационных порталов: специфика при сборе ключей
Основное отличие при сборе ключевых фраз для стандартного коммерческого ресурса и новостного сайта в частоте подбора. К примеру, на блоге или форуме свежий материал публикуется чаще, чем на сайте другой направленности.
Поэтому ключевые фразы под каждую новую страницу опубликованного поста следует находить каждый день.
Не обязательно находить много ключей, некоторые новостные сайты обходятся 2-3 ключевыми фразами на статью.
Следствие из такой ситуации — весомость выбранных ключевых фраз, и важность их правильного выбора.
Важно также подбирать те ключевики, которые соответствуют контенту страницы. Релевантность имеет значение, так как влияет на поведенческие факторы пользователей, и ранжирование сайта в поисковой выдаче. Для информационных сайтов это особенно актуально, — читатель не захочет переходить на страницу того ресурса, который выдал его запросу нерелевантный пост.
Как собирать семантику
Для подбора ключей используем сервис Serpstat. Вводим ключевое слово интересующей тематики (в нашем примере “властелин колец”), выбираем поисковую систему, и переходим в раздел “Подбор фраз”.
Если проверять фразы на мусорность и релевантность вручную, экспортируем данные в удобном формате. В противном случае отмечаем найденные ключевые слова, и заносим их в список, который хранится на сайте.
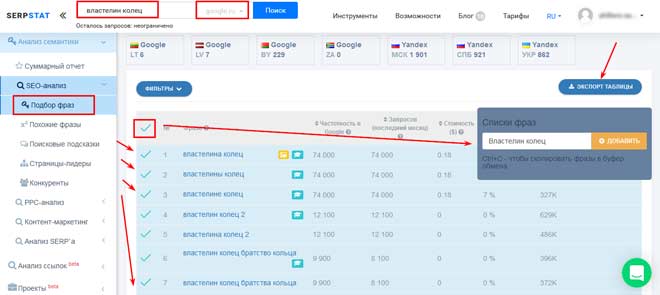
Далее переходим в раздел “Похожие фразы”. Аналогично экспортируем ключевики при ручном отсеивании. Для проверки релевантности на сервисе, вносим ключи в уже созданный список, нет необходимости создавать новый.
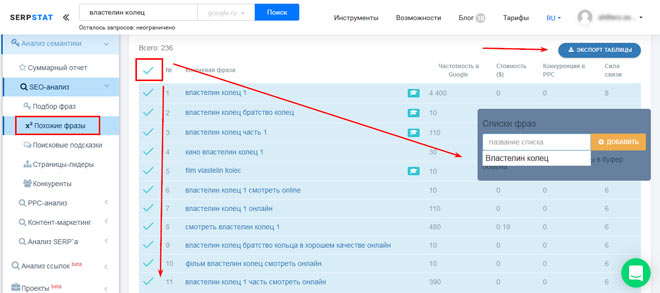
После этого переходим в раздел “Поисковые подсказки”. Экспортируем их в удобном формате. Подсказки позволяют не только пополнить СЯ, но и подобрать темы для статей, которые популярны среди пользователей.
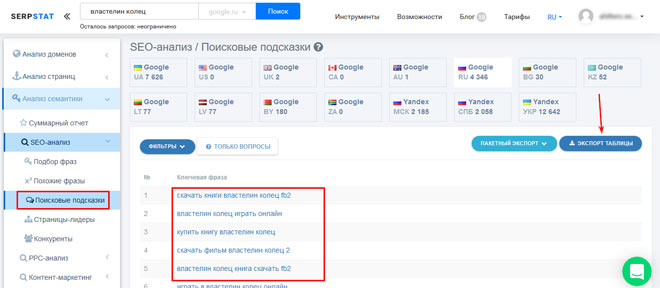
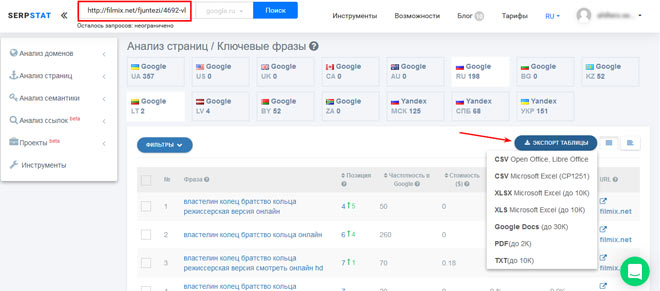
Существенной составляющей семантики являются ключевые фразы, которые содержат наиболее перспективные страницы конкурентов. Для того, чтобы их определить, заходим в раздел “Страницы-лидеры”, и группируем информацию по уровню потенциального трафика.
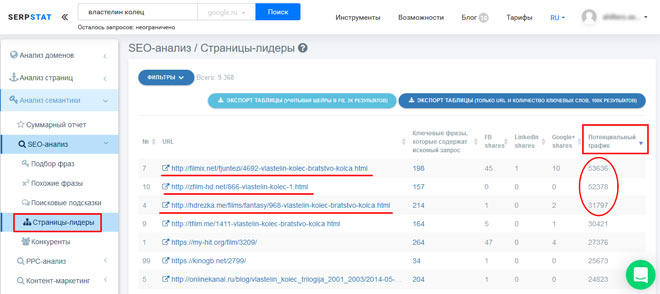
Перспективные страницы ранжируются по наиболее качественным, релевантным ключевикам. Поэтому кликаем по адресам самых успешных страниц, и получаем лучшую семантику.
Как провести проверку собранных ключей
Не напрасно поисковые системы учитывают не только количество ключевых слов, но и качество. Это позволяет составить наиболее полезную пользователю поисковую выдачу. Поэтому важным этапом в составлении СЯ является анализ и отсеивание мусорных и не релевантных ключевых фраз.
С помощью Serpstat анализ и очистка собранных ключевиков проводится в разделе “Инструменты”.
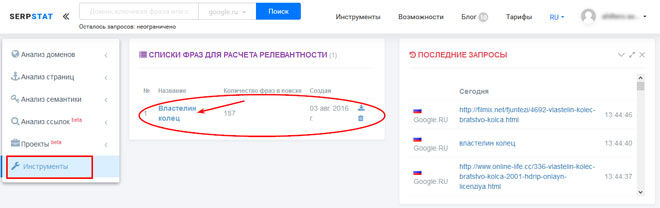
Для проверки релевантность собранных фраз странице сайта необходимо кликнуть по названию списка слов. Теперь выбираем страницу сайта (в нашем примере tolkienists.ru), и слова, по которым рассчитывается релевантность.
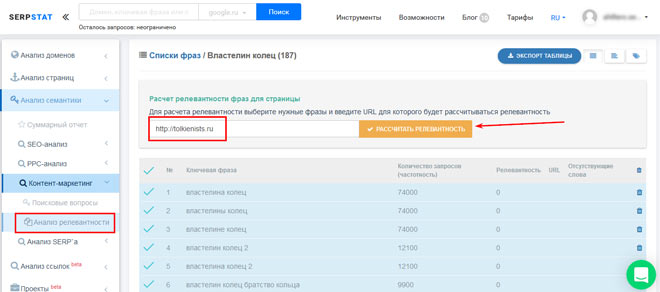
В нашем примере ключевые слова обладают низким уровнем соответствия странице. Если создаем контент, который схож с тем, что содержит проверяемая страница, следует поработать над ключевыми словами. Необходимо добавить отсутствующие слова, составить рабочие ключевики, либо отбросить абсолютно не релевантные фразы.
Далее проводим проверку фраз на “мусорность”. Такими называют те словосочетания, которые бессмысленны, и при использовании сбивают с толку поисковые системы.
В том же разделе “Инструменты” выбираем “Добавить ключевые слова” напротив функции “Проверка качества ключевых слов”. В Serpstat, самая большая чистая база ключевиков Yandex, поэтому вручную вносим только те ключевые слова, которые вызывают больше всего сомнений. На данный момент доступны проверки по трем регионам Yandex, а именно Москва, Санкт-Петербург и Украина.
Результаты проверки приходят спустя 20-30 минут на почту.
Итоги:
В первую очередь мы определили, что представляет собой специфика в составлении СЯ для информационного портала. Далее, отталкиваясь от нее, проводили сбор семантики и проверяли полученные ключи на качество.
Сбор ключевиков делали с помощью следующих средств:
- Подбирали фразы и синонимы
- Использовали поисковые подсказки
- Анализировали семантику перспективных страниц конкурентов
Когда получили пул ключевых фраз перешли к их очистке и анализу на релевантность. Очистку провели инструментом Serpstat — проверки фраз на мусорность. Релевантность проверили по отношению к схожей странице конкурента.
На этом у меня все.
С уважением, Александр

Поделись с друзьями:
Обратите внимание:
Похожие статьи

© 2024 Блог Александра Бобрина. Создание сайта и заработок в интернете · Копирование материалов сайта без разрешения запрещено
Политика конфиденциальности | Пользовательское соглашение
Хороший сервис, но не подъемно дорогой пока для меня.
Читал, что семантическое ядро для блогов не столь актуально, как для коммерческих сайтов. Что можете сказать?
Отличный сервис!
Частенько в нем число запросов проверяю.
А вообще больше нравиться мегаиндекс, спайвордс — тоже не плохой=)
Сервис действительно не из дешевых. По-моему дешевле купить кей-коллектор и парсить сколько угодно долго. Ну или на худой конец есть аналог бесплатный СлоВоЕб. ))
Согласен, что Кей Коллектор получше будет, надо только к нему привыкнуть. Бесплатная версия слишком убога, но в качестве затравки пойдет. И парсить-парсить конкурентов.
Ресурс довольно удобен, под игровые автоматы семантику только на нем удалось собрать
По-моему дешевле купить кей-коллектор и парсить сколько угодно долго.